目前的NLP任务中,我们对于词汇表的处理通常是直接按词频截断,但这种方法并不一定科学,理论上,词的重要程度应该是遵循某种分布的(自然界的东西大都遵循某种分布),使用变分估计可以估计出样本的分布。本文提出了一个称为变分dropout的方法,使用变分法估计词的重要性分布,并选择性的划分词表,结果表明,相比直接对词表按阈值划分,这种划分方法效果更好。
(这篇论文阅读于2020年5月,GCN的几个方向被否后,导师让我自己找别的方向,因为疫情的原因并没有开学,所以只能在家自己摸索一下,我看了一下倒腾了一下这篇论文。本论文发表于ACL 2019)
简介
目前的NLP任务中,我们对于词汇表的处理通常是直接按词频截断,但这种方法并不一定科学,有些高频词可能并不重要(即使是去掉停用词后),而有些低频词可能很重要。而且,截断词汇表的词频阈值往往也依赖于编程者的项目经验,我们并不知道何种频率最好。
根据本文的统计,在一个简单的基于CNN的文本分类模型中,嵌入层的参数占了模型的大部分参数, 这可能成为许多模型在实际应用中的阻碍,尤其是在一些低算力场景下。

其中:#Emb是单词嵌入矩阵中的参数数量(256维),#CNN是CNN模型中的参数数量。
为了减轻这种冗余问题并使嵌入矩阵尽可能高效,本文期望寻找出一个最小化嵌入矩阵,使得在使用尽量少的词汇的情况下,和保留了完成词汇的嵌入矩阵有基本相似的性能。
本文提出了两个问题:
- 词汇选择算法在文本分类中起到什么程度的作用?
- 如何在保持准确性的同时大幅减少词汇量?
简单的说,词汇选择就是对总词汇库进行采样,本文探究的是如何采样才能尽量少单词同时保留尽量多的语义。
变分估计法可以估计出某组数据的分布,根据估计出的分布,对词表进行有选择性的提取,可以提升模型的性能。
(由于我没弄懂变分估计法,所以就不再继续介绍变分法)
本文的贡献如下:
- 本文正式定义了词汇选择问题,展示了其重要性,并针对文本分类任务中的词汇选择提出了新的评估指标。
- 提出了一种新的基于变分采样的词汇选择算法,该算法通过在贝叶斯推理框架下重新构造文本分类来实现。
- 进行了全面的实验,以证明所提出的词汇选择算法在许多强基准上的优越性。
关于词汇选择的重要性
在给定总计为V的词汇的情况下,存在一定的算法可以从完整词汇V中选择不同的词汇子集 。但列举所有的采样的可能性是不可能的。
本文设计了一种蒙特卡洛模拟策略,以近似估计可能的选择算法A所达到的给定词汇量的准确性的下界和上限,通过运行N次来模拟可能的选择算法。

结果显示,在较低的词汇量下的精度的波动范围非常大,当采样的词汇量增加时,差距逐渐缩小。这样的蒙特卡洛模拟研究证明了词汇选择策略在NLP任务中的重要性。
评估指标
作者使用了两种指标:曲线下面积(AUC)和Vocab @ -X%
AUC测量全局性能。AUC通过曲线计算封闭区域,从而概述了词汇选择算法的性能。这里的AUC的横坐标是词汇量,纵坐标是准确度。
Vocab @ -X%局部词汇选择性能。Vocab @ -X%指的是,当允许X%性能下降时,则Vocab @ -X%计算所需的最小词汇量

文章任务发现直接计算AUC过于强调大词汇量区域,因此无法代表算法在低词汇量条件下的选择能力。因此,本文采用词汇量的对数建立坐标系,再计算AUC。
词汇选择方法
作者从dropout的思想提出了单词级dropout。作者假设每个单词wi有一个与其特征相关dropout率pi,代表其被空的占位符替换的可能性,具体来说,dropout率越高,表示从词汇表中删除它所造成的损失就越少。
则原始优化问题可以认为是推导潜在的dropout概率向量p = [p1,…,pV]。
作者一共提出了两种dropout方法:伯努利dropout、高斯dropout。
作者只使用这两种方法的原因应该是,提出变分编码的论文《Auto-Encoding Variational Bayes》中就只使用了伯努利dropout和高斯dropout,本文的大部分思路来自于这篇论文。
另外根据苏剑林的博客中关于《Auto-Encoding Variational Bayes》的分析中提到:
使用变分法,需要构造一个分布,而不是任意一个函数,既然是分布就得满足归一化的要求,而要满足归一化,并且要容易计算,就没有多少选择了。
伯努利dropout
将给定的单词x投影到向量空间 中,然后将随机的dropout噪声添加到嵌入输入中以模拟dropout过程,如下所示:
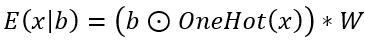
OneHot是将单词x转换为one-hot形式的函数,OneHot(x)∈R(V),而b∈R(V)是bi〜Bern(1- pi)的伯努利dropout噪声。本公式指的是:在进行伯努利抽样的向量b下,使用给定的嵌入矩阵W计算嵌入输出向量E(x|b)。
为了在给出训练对(x = x1…xn,y)作为证据的贝叶斯框架,下推断带有参数p的潜在伯努利分布,首先将目标函数定义为
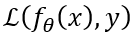
(L是证据下限(ELBO)函数),然后按如下方式推导其下界:
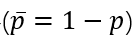
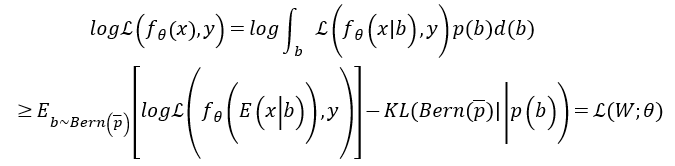
其中P(b)是先验分布,而
表示参数为p的伯努利近似后验。KL是指K-L散度(Kullback-Leibler Divergence),是一种量化两种概率分布P和Q之间差异的方式,又叫相对熵。
整个优化目标是:寻找一组参数使得先验分布和近似后验尽量的接近。即,使得
尽量的小,也就是使得ELOB函数的值尽量的大。
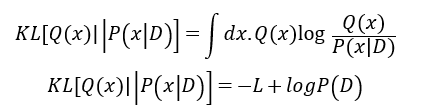
Q(x)为要近似的分布,P(x|D)为参数x的条件概率分布, lnP(D)为log似然,L为log似然的下界。
高斯dropout
由于伯努利分布是一个二元分布,故通过伯努利分布进行计算时需要对样本进行采样,作者的说法是,计算一次随机dropout向量b的期望需要使用2 V个不同的值来计算。因而作者使用连续高斯进行近似,这个方法是《Auto-Encoding Variational Bayes》中提出的。
和伯努利dropout类似,假设模拟计算过程如下:
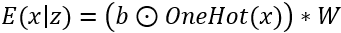
其中z∈R V遵循高斯分布(正态分布):
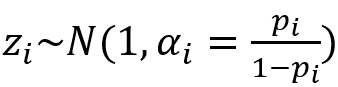
将b合并到W中,即将b当成嵌入权重B本身的内在随机特性,此时:
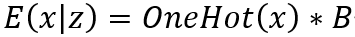
其中
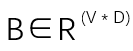
且遵循多元高斯分布:
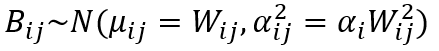
下界推导过程和伯努利dropout类似:
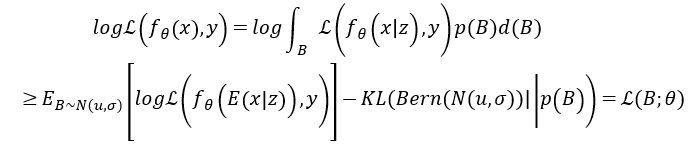
词汇选择
经过学习优化,可以获得与每个单词wi相关的dropout率αi。本文使用了阈值αT来根据dropout率选择词汇子集。因此,剩余的词汇子集描述如下:
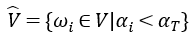
通过调整αT,可以控制所选词汇表的大小。
总结
我实际上没有跑通这个东西(python2+tensorflow0.X的祖传代码,甚至不是1.X的版本),只是捋清了项目的代码主干,然后搬到了itag中试了一下。但这个在上古代码里掏方法到新框架里的体验让我学到了很多。
就结果来说是有提升的(这个方法放在任何NLP任务中应该都有所提升),但是我的导师表示这个的创新性更加不足,往itag上套个变分纯粹只是为了提高而提高,没有任何可以用来写论文的点,最后这个方向也停了。
这轮实验之后,我完全放弃了文本的标签推荐方向,转而开始做跨语言信息检索方向。