去年入学后导师丢给我的第一篇论文, 让我看这篇论文和tag推荐相关的其他论文,让我自己找改良方案。这篇论文的模型被作者命名为itag。
(论弹射起步,默认我全懂+上来让我改良顶会论文)
论文背景
本文提出了一种基于Seq2Seq的文本多tag推荐模型。读入序列为文本内容,输出序列为tag。
由于Seq2Seq模型的输出是一个序列,因此用Seq2Seq做多tag推荐天然优于那些单靠全连接层+softmax的模型。
(官方提供一个py2版本的代码,我基于官方版本修改出了一个支持py3的版本,使其能支持高版本CUDA)
论文分析
这篇论文其实很有意思,运用了NLP领域中多种常见的技术,完美的缝合怪(没有指摘的意思,做完美缝合怪是一件难度很大的事),作为入门论文也很好,硬吃下来需要查阅了解它用到的所有的技术。
创新点分析
论文声称,他们考虑了多标签推荐任务的特性,提出了多标签推荐任务的三个要素:
- 文本内容建模
- 标签相关现象
- 内容-标签重叠
文本内容建模:使用合适方法对文本进行建模,这一点对于一切NLP任务都是最重要的,如果无法对文本进行合适的建模,那后续步骤就注定不会太好。作者在这里婊了一下TF-IDF这一类的主题词模型,声称使用结合了注意力机制RNN建模效果更好。
标签相关现象:标签之间并非是独立的,标签间存在着一定的关系,例如语义重叠——两个标签的意思可能是接近的,或者子母类别标签——出现Apache标签则很大可能出现Java标签,反之不亦然。能够捕捉到这些信息显然对于tag推荐任务是有帮助的。
内容-标签重叠:一些单词会在文本中出现,同时这些单词又会作为标签出现。例如文本中提及JAVA的话,tag中带有java的可能性就会提高。
个人认为,三个点都不算是特别创新的点。例如,作为一篇2019年的论文来说,大可不必去鞭尸TF-IDF这样的老方法,RNN的文本建模能力显然是强于老的主题模型的。(然后现在RNN快被bert干烂了,三十年河东三十年河西)。
标签相关现象也是多标签推荐中早就被注意到的问题,古早的方法是使用贝叶斯概率(已经有标签X之后,文本还有标签Y的概率)、决策树(将标签构建成树)、将多标签任务转换为标签对任务。但本文使用RNN进行多标签输出是一个相当新颖的点,RNN解码器自然的建模了标签间的互动关系,不需要手动设计特征,也比基于统计学的传统方法效果好。
内容标签重叠也不是特别新颖的点,Tag2Word(CIKM 2016)就是使用了这个思路,但作者实现的方法很有新意,将在后面的模型分析中说明。
模型分析
如前所述,本篇论文并没有提出什么开创性的新算法或者新模型,只是一个结合现有方法的缝合怪,但是缝合的极其完美。
本文的模型的骨干是一个三层GRU的Seq2Seq模型,在这个模型上使用了共用嵌入层、attention机制,另外还有一个作者在论文中称为指示函数(Indicator Function)的机制。
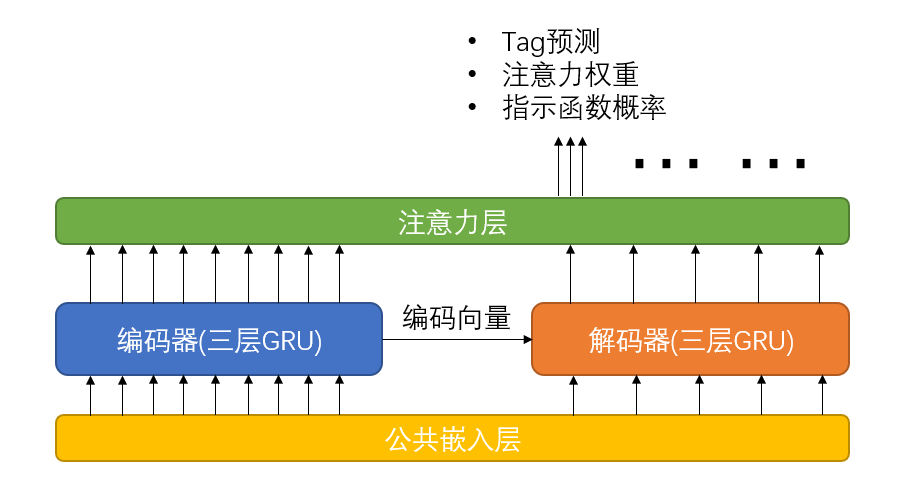
不同于通常的seq2seq模型,本论文的模型除了输出tag概率外,还同时输出注意力权重和指示函数输出的概率值。
根据论文的描述,这个指示函数指示直接从正文中复制一个单词作为tag的概率。这个指示函数和公共嵌入层共同构成了论文的内容-标签重叠机制。但据我观察,这个指示函数在代码中并没有实际使用(具体情况后面具体分析)。
共用嵌入层
所谓共用嵌入层是指,文本和TAG都使用一个嵌入层进行嵌入。通过使用共用嵌入层,可以一定程度上实现内容-标签重叠,文本中的单词“java”和tag中的“java”会获得同一个嵌入向量,有利于解码器理解编码器传递过来的信息。
具体来说,使用共用嵌入层之后,词/tag空间的编号方式如下

其中独立单词是指没有作为tag出现过的单词,公共单词是指既在文本中出现过,又作为tag出现过的单词,独立tag是指只作为tag出现过的单词。
使用共通嵌入层之后,解码器的行为需要进行一定的调整,解码器的预测宽度=共通单词+独立tag,而非全部单词。因而输出时,需要将softmax的输出映射到这个公共词汇表中。

根据我的测试结果,移除掉这个共通嵌入层之后(改用两个独立的嵌入层),模型性能下降约1~2个百分点。
Attiention机制
Seq2Seq模型使用attention机制是常规操作,不对其本身进行过多分析,作者另外强调了一点,结合了attention机制的GRU编码器,能捕捉到的高权重词汇,除了编码文本外,一定程度上还能起到TF-IDF这种主题词模型的作用。
本论文的创新在于,在这个attention机制上,作者使用了一个直接定向学习权重的方法,来辅助学习attention权重。通过让模型直接输出attention权重,直接对attention权重进行定向学习。这个机制的具体描述如下。
Attention机制有利于使模型注意到输出序列和输入序列中某些词的对应关系(如图所示)

而在seq2seq的tag推荐任务中,假定输入文本长度为100,目标tag为“python”,输入文本中存在单词“python”,且位置在34时,最完美的注意力系统应该将全部的注意力权重都放在34上。
而在本论文的模型中,通过事前的数据处理,将解码器的目标attention权重设定为[0,0,…,0,1,0,…,0,0](其中第34位为1)。
而对于tag对应的单词在文本中出现多次的情况,则将对应位置全部标记为1,而非强行one-hot编码,毕竟如果这个单词反复出现的话,attention权重理应分部到全部的出现位置上。
使用这个机制后,attention权重由tag预测部分的loss和直接指示的权重的loss共同影响。
指示函数
前面提到过,模型的指示函数是个没有实际用处的空架子,作者关于这个指示函数的描述是:学习pi之后,我们以pi的概率直接在当前文本中复制一个单词,选择的单词由公式中的注意力权重αij决定。
而在代码中,指示函数概率的最终输出部分是一个输出宽度为1的softmax,这个输出无论什么情况下都恒为1。
另外,这个指示概率生效的部分在预测部分,学习部分只输出这么一个值,没有任何关于这个值的学习目标。
预测部分涉及到这个指示函数的部分如下
1 | if (en[i] - LABEL_FROM) > 0 and (en[i] - LABEL_FROM) < DE_TOKENS: |
en:编码序列
LABEL_FROM:在共通嵌入层中,tag开始的位置
DE_TOKENS:tag预测的输出空间大小
new_prs:一次预测输出的概率序列
weights:attention权重
pgen:指示函数输出的概率(即描述中的pi)
这段代码解释是,如果正文中的一个词在tag范围内,提升其作为tag 的概率,提升的幅度由这个词的注意力权重和pgen共同决定。
想法极好,然而pgen输出恒为1,这段代码等于没有任何作用。
其他机制
另外作者使用了一个窗口大小3的为beam search提升tag预测精度,RNN的seq2seq常规操作,不进行太多分析。
数据集&Baseline
数据集来自三个论坛
- Ask Ubuntu
- Mathematics Stack Exchange
- Stack Overflow
没有什么特别值的一提的点,非要说的话,这篇论文的源码在数据处理部分一点也不讲究。目标输出的one-hot化、输入文本、输出tag的填充和截断全都是事前进行,完全没有并行化处理。而最大的Stack Overflow和中等大小的Ask Ubuntu让我的2070S瞬间暴毙,只有最小的Mathematics Stack Exchange可以完全加载,因此我复现的结果实际上没有用全部数据集。
Baseline
- TagSpace (Weston, Chopra, and Adams 2014) :基于CNN的tag推荐模型
- Maxide (Xu, Jin, and Zhou 2013):一个经典而传统的多tag推荐模型
- Tag2Word (Wu et al. 2016):通过内容-标签重叠进行标签推荐一个算法
- ABC (Gong and Zhang 2016):一个基于attiention机制和CNN架构的标签推荐模型
- TLSTM:通过attiention机制,结合了LSTM和LDA进行标签推荐的模型
当时,导师在我调通itag之后,直接让我再跑通itag的Baseline。其中1、2、3、5我跑通了,1、2、3有现成可运行的源码,定向调整了数据集结构就可以了。5没有现成可运行的源码,最终自己实现了一遍。
论文总结
跳过结果分析,毕竟结果差的话这论文也发不出来,除非结果中有什么特别值的分析的现象还能提一嘴,然而没有。
如前所述,这个论文的模型堆叠了大量的NLP领域的成熟的机制,并且堆得相当完美。根据论文自己的描述,这些机制和三大改良点的对应关系如下
- 文本内容建模:三层GRUs+attiention
- 标签相关现象:三层GRUs+beam search
- 内容-标签重叠:公用嵌入层+指示函数
其中指示函数这部分机制存疑,因为代码中的这部分代码实际上没有作用
最开始看到论文的时候,第一感觉:这是啥玩意儿?怎么和我学的东西完全对不上?
(当时我只学完了吴恩达的机器学习+深度学习,除了RNN和attiention有提及之外,其他的对我来说是全新的东西)
看了一个月之后:就这?seq2seq+attiention?我上我也行。
做了一年之后:这缝合怪真nm完美,我上我不行。